Businesses struggle to use centralized data lakehouse data (like Databricks) for real-time operational decisions due to the technical debt and latency of data copying.
This article outlines a “Zero Copy” architecture that transforms the lakehouse into an active intelligence engine. By leveraging Change Data Feed (CDF) and a best-of-breed streaming stack (Kafka/Flink), raw data changes are immediately captured, enriched into high-value business events, and made actionable end-to-end in under five seconds (p95).
This approach eliminates data duplication, delivers superior performance and flexibility, and finally closes the loop from data to instant action.
- Introduction: The Data Lake Dilemma
Businesses today have successfully consolidated their most valuable data—orders, member profiles, behavioral events—into a unified data lakehouse like Databricks. This has been a massive leap forward for analytics and AI. Yet, a critical gap remains. While this data is perfect for historical analysis, using it to power real-time operational decisions, like triggering a marketing journey or personalizing an experience, is a constant struggle. The typical solution involves creating brittle data pipelines, data drift, and significant technical debt by copying data into separate operational systems.
This approach is fundamentally inefficient. It creates a lag between when an event happens in the business and when you can act on it, increasing operational overhead as multiple copies of data are managed and governed. This raises a central question for any modern data team: What if you could activate your lakehouse data for real-time use cases without ever copying it?
A modern architectural pattern proves this isn’t just a hypothetical question—it’s an achievable reality. By combining the power of a data lakehouse with a best-of-breed streaming stack, you can close the loop from data to intelligence to action. This post breaks down the four most impactful takeaways from this “Zero Copy” architectural design.
2.0 Takeaway 1: Your Data Lakehouse Isn’t Just for Analytics—It’s Your Real-Time Source of Truth
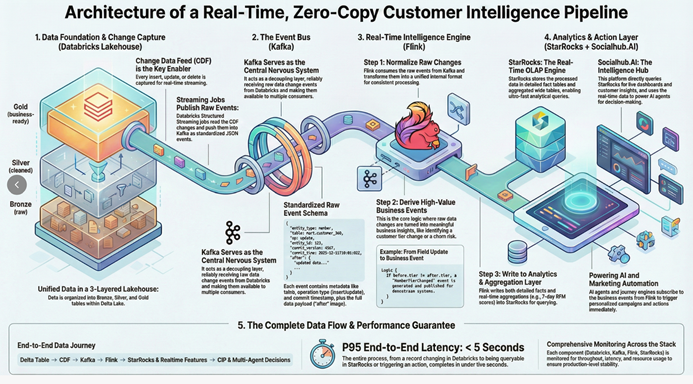
The foundational principle of this architecture is “Zero Copy.” This means no raw, detailed data is ever duplicated outside of Databricks. The lakehouse, which already serves as the single source of truth for analytics, is elevated to become the single source of truth for real-time operations as well.
This is achieved by activating the Change Data Feed (CDF) feature on key Delta Lake tables. Instead of scheduling slow batch jobs to query and export entire tables, a Databricks Structured Streaming job simply subscribes to the stream of changes—every insert, update, and delete—as they are committed to the Delta table. The job then constructs a standardized ‘Raw Change Event’ for each change and publishes it to a dedicated Kafka topic.
This represents a significant paradigm shift. The data lakehouse is no longer a passive repository waiting for batch queries. It becomes an active, event-driven engine that serves as the central nervous system for the entire business, broadcasting changes the moment they occur. All downstream systems react to this single, authoritative stream of facts, eliminating data drift and the costs associated with data duplication.
3.0 Takeaway 2: The Real Value Isn’t Moving Data, It’s Creating Meaning from Change
Simply streaming raw database changes (field X changed from A to B) is not enough to drive intelligent action. The real magic happens in the stream computing layer, powered by a tool like Apache Flink, which transforms low-level data changes into high-value business events.
This is where raw data is interpreted and enriched with business context. Consider these concrete examples of how raw field changes from a customer_360 table are translated into meaningful business signals:
- A change where before.tier != after.tier is not just a data update; it becomes a MemberTierChanged event.
- An update where after.lifetime_value crosses a predefined high-value threshold becomes a MemberBecomesHighValue event.
- A status change where after.status flips from active to inactive becomes a critical MemberChurned event.
The output is a well-structured business event, such as a MemberTierChanged event containing the member ID, a new event ID, and a payload detailing the change from ‘Gold’ to ‘Platinum’.
This is the core differentiated capability of the architecture. It turns low-level database chatter into high-level business intelligence. Flink then follows a dual-path process: it simultaneously (1) publishes these discrete, high-value business events to a Kafka topic for immediate consumption by action layers like a journey engine, and (2) writes enriched, queryable data (both detailed facts and real-time aggregations) to StarRocks for analytics and insight.
4.0 Takeaway 3: Five Seconds From Data Lake to Actionable Insight is Now Reality
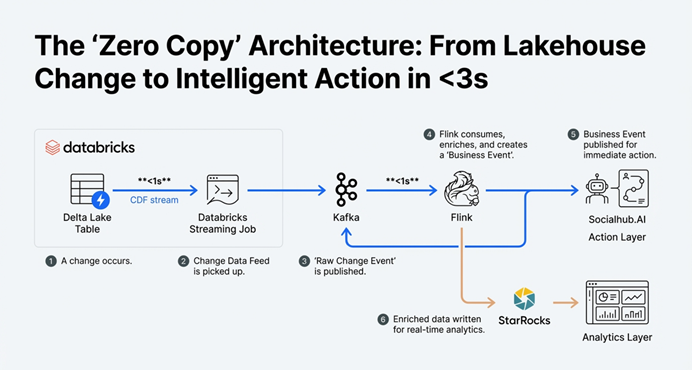
A common and valid reservation about using a data lakehouse for real-time operations is the perceived latency. Traditional lakehouse architectures are associated with batch processing, where delays of minutes or even hours are acceptable. This architecture definitively dispels that myth.
The target Service Level Agreement (SLA) for this system demonstrates that high performance is not a compromise.
The overall end-to-end latency (from a write in a Delta table to the data being queryable in StarRocks or the event being consumable) is a p95 of less than 3 seconds.
This remarkable speed is the sum of a hyper-efficient pipeline: change visibility in the Delta Lake CDF is near-instantaneous (seconds), the Databricks streaming job reads the change and writes to Kafka with a p95 latency under one seconds, and the Flink job processes and lands the result in under one seconds (p95). The business implication of this speed is profound: it enables the ability to understand and react to customer behavior almost instantly.
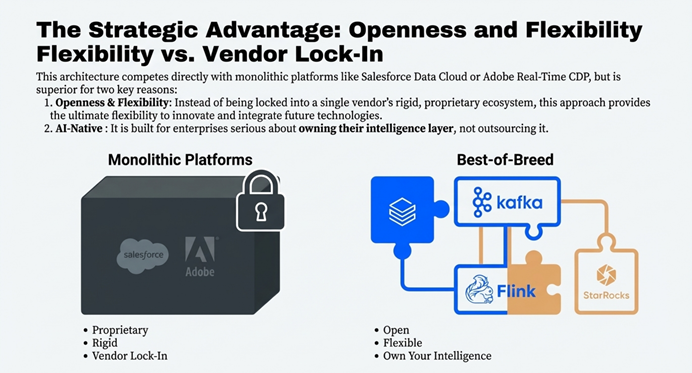
5.0 Takeaway 4: A Modular “Best-of-Breed” Stack Provides Ultimate Clarity and Scale
This architecture is built on a logical pipeline where each technology is chosen for its specific strengths and has a single, well-defined responsibility. This ‘best-of-breed’ approach not only provides exceptional clarity and scale but also enables robust, production-grade operations through clear monitoring boundaries and component-specific SLAs.
The roles within the stack are clearly separated:
- Databricks: Unified data storage, governance, and raw change event production via CDF.
- Kafka: The decoupled event bus and buffer layer, enabling multiple downstream consumers.
- Flink: The real-time business logic, enrichment, and aggregation engine.
- StarRocks: The high-performance OLAP serving layer for real-time analytics and ultra-low-latency queries on both detailed and aggregated data.
- Socialhub.AI: The intelligence and action layer that consumes prepared insights to power AI agents and orchestrate customer journeys.
This clear separation of concerns is also a powerful strategic advantage. This architecture competes directly with monolithic platforms like Salesforce Data Cloud or Adobe Real-Time CDP, but it is superior due to its openness and AI-native flexibility. Instead of being locked into a single vendor’s rigid, proprietary ecosystem, this best-of-breed approach provides the ultimate flexibility to innovate and integrate future technologies, positioning it as the more modern choice for enterprises serious about owning their intelligence layer.
6.0 Conclusion: From Passive Data to an Active Intelligence Engine
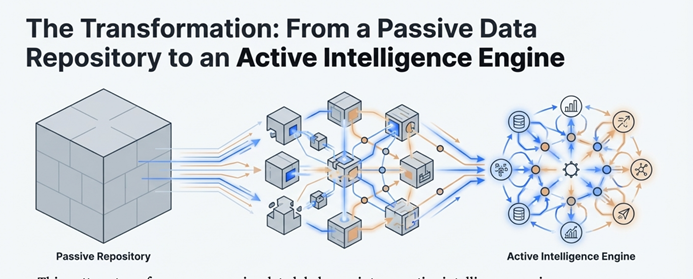
By strategically combining a data lakehouse with a real-time streaming stack, it is entirely possible to build a “Zero Copy” architecture that is incredibly fast, efficient, and intelligent. This pattern transforms a passive data repository into an active intelligence engine, directly connecting your core data assets to real-time operational execution without the technical debt and latency of traditional data duplication.
This isn’t just another technical pattern; it’s a strategic choice. It proves you no longer have to choose between a unified data platform and real-time operational capability. For businesses that want to own their intelligence layer and outmaneuver competitors locked into rigid, proprietary ecosystems, this approach closes the loop “from data to intelligence to execution.” It leaves only one question to consider:
If your core business data could safely power real-time decisions in under five seconds, what customer experiences would you reinvent first?